JavaScript SEO: How I Diagnose and Fix Rendering Problems on Client Sites
Listen to this article
Browser-native voice. No account required.
A site can look perfect in the browser and be half-invisible to Google. That gap is where JavaScript SEO lives, and it is where a lot of expensive redesigns quietly lose their rankings.
Google can render JavaScript, but not instantly and not always the way you assume. This is how I diagnose whether Google actually sees a JS-dependent site's content, the rendering problems that hide it, and the fixes I apply. It is the part of a technical SEO audit that catches the issues a content review never would.
What Is JavaScript SEO?
JavaScript SEO is the practice of making JavaScript-dependent content crawlable, renderable, and indexable by search engines. It covers how Googlebot processes JS, why content rendered in the browser can be missed, and the rendering and linking choices that decide whether a JS site ranks. It is a technical discipline, not a content one.
It matters most for sites built on frameworks like React, Vue, or Angular, where the initial HTML can be nearly empty and the real content is assembled by JavaScript after the page loads. If Google never runs that JavaScript, or runs it late, the content is effectively missing.
Can Google Crawl and Index JavaScript?
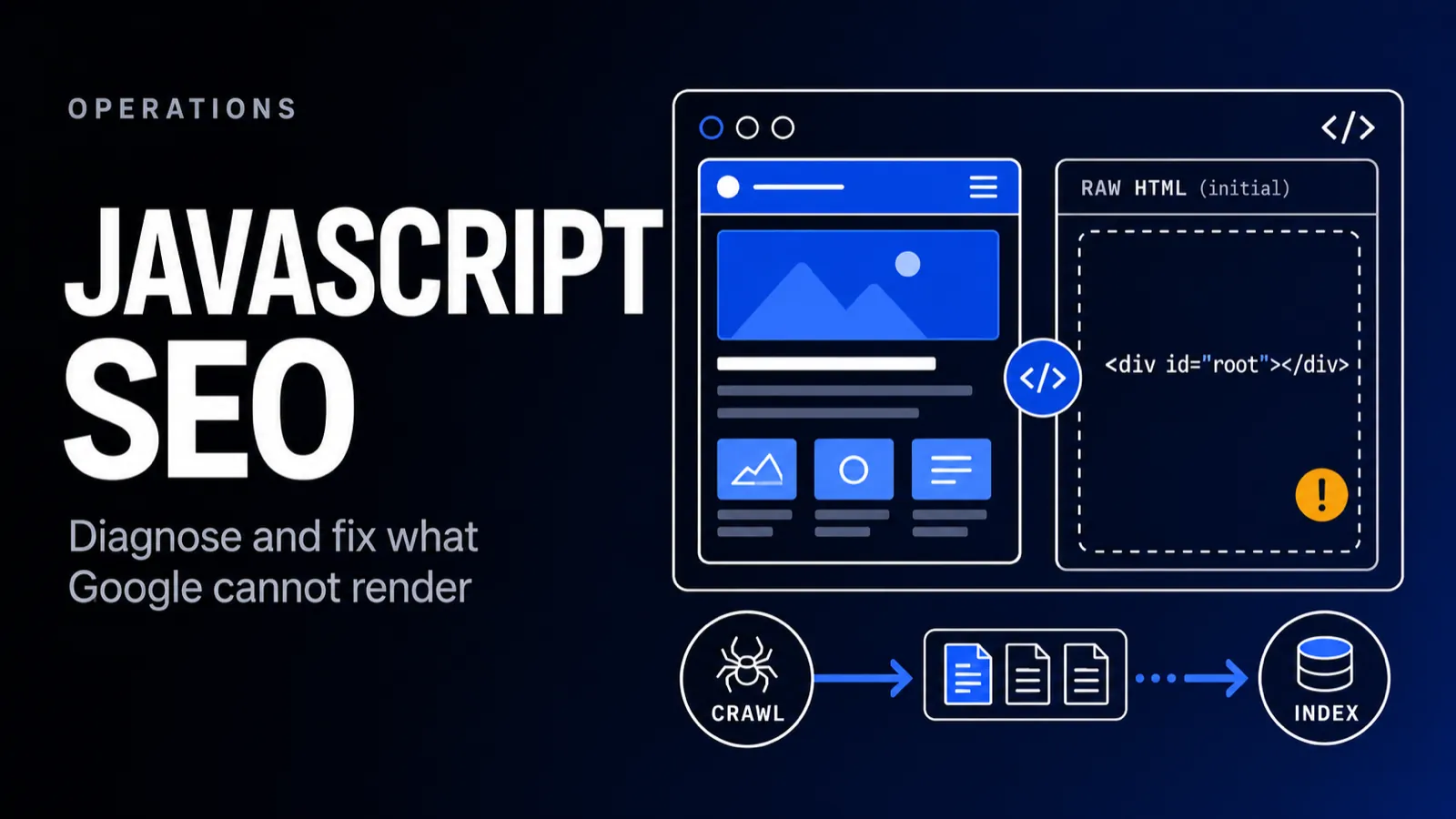
Yes, Google crawls, renders, and indexes JavaScript, but on a delay. It fetches the raw HTML first, queues the page for rendering, then runs the JavaScript in a headless browser before indexing the rendered result. That deferred render is the catch: content that only appears after JS executes waits in line to be seen.
Other search engines and most AI crawlers are far less capable. Many do not execute JavaScript at all. So "Google can handle it" is not the same as "everyone can handle it," and Google's own JavaScript SEO documentation is explicit that rendering is resource-limited and deferred.
How Google Renders JavaScript
Googlebot processes a JS page in three stages: crawl, render, index. It first fetches the raw HTML without running any JavaScript. The page then enters a render queue, where a headless Chromium runs the JS when resources are available. Only the rendered DOM, the page after JS has executed, gets indexed.

The render queue is the part most people miss. Rendering can trail crawling by anything from minutes to days depending on the site and Google's capacity. For a news site publishing time-sensitive content client-side, that lag alone can mean the difference between ranking and missing the window entirely.
Common JavaScript SEO Problems
Most JS SEO issues come down to one thing: content or links that exist for users but not for the crawler at the moment it matters. These are the ones I find most often on client audits.
Content Missing from The DOM
The most common problem is content that never makes it into the rendered DOM Google indexes, or only appears after an interaction. If the main content depends on an API call that fails, times out, or requires a click, Google may index an empty shell. Your React app renders beautifully for users and hands Googlebot an empty div.
I see this most on single-page apps where the homepage looks rich but view-source is a near-empty body with one script tag. Users never notice because their browser runs the JavaScript instantly. Googlebot, fetching the raw response first, sees almost nothing until the render queue catches up.
Links Google Cannot Follow
Google follows links that are real anchor tags with an href attribute. A <div onclick="router.push()"> that routes via JavaScript is not a link Google can crawl, so the pages behind it may never be discovered. Pagination, faceted navigation, and "load more" buttons built without real hrefs orphan everything downstream of them.
The fix is simple and the audit catches it fast: every link that should pass equity or be discoverable needs a real href pointing at a real URL. Keeping the JavaScript routing for the click behavior is fine, as long as the anchor underneath is genuine.
Lazy-Loaded Content and Infinite Scroll
Content that loads only on scroll or interaction is a risk, because Googlebot does not scroll or click the way a user does. Infinite-scroll feeds with no paginated URLs, and images or text that load only when in view, can be invisible to the crawler. The content has to be reachable without a user gesture.
The standard fix is to back the infinite scroll with real paginated URLs Google can crawl, and to use native lazy-loading for images so the markup is present even before the image loads. The user keeps the smooth scroll; the crawler gets a path to every item.
Blocked JavaScript Resources
If the JavaScript and CSS a page needs to render are blocked in robots.txt, Google cannot render the page properly and may index a broken version. This is a self-inflicted wound I still see regularly: a blanket disallow on a /static/ or /assets/ directory that quietly stops the page from rendering at all.
It is easy to introduce by accident during a migration, when an old robots.txt rule carries over to a new framework that serves its bundles from a different path. The rendered-HTML check catches it immediately, because the screenshot Google generates comes back broken or unstyled.
Slow or Failed Hydration
Hydration is when client-side JavaScript attaches to server-rendered HTML to make it interactive. When hydration is heavy or fails, the page can be slow, shift layout, or break interactivity, hurting both Core Web Vitals and the user experience. A page that takes seconds of JS work before it is usable is a ranking and conversion problem at once.
Server-rendered content that depends on hydration to function can also leave users staring at a page that looks ready but does not respond. The content indexes fine, but the experience signals and conversions suffer, which is its own SEO cost over time.
How I Diagnose JS Rendering Issues
Diagnosis is about comparing what the browser shows a human with what Google actually renders. The browser is a liar here, because it always runs the JavaScript. These are the checks that show the truth.
The Rendered-HTML Check
The fastest reliable check is Search Console's URL Inspection tool, which shows the rendered HTML Google sees and a screenshot of the rendered page. I compare that against the live page. If the main content, links, or metadata are present for me but missing in the rendered HTML, I have found the problem and confirmed it with Google's own renderer.
View Source Versus Inspected DOM
A quick first pass is comparing view-source (the raw HTML) with the inspected DOM (after JS runs). If content is in the inspected DOM but absent from view-source, it is being added by JavaScript and depends on rendering to be indexed. The Mobile-Friendly Test and Rich Results Test also expose the rendered HTML, as Ahrefs covers in its JavaScript SEO breakdown.
Crawl with Rendering On
For a whole-site view I run a crawler such as Sitebulb or Screaming Frog in JavaScript-rendering mode, then compare the rendered crawl against the raw one. Pages that have content and links in the rendered version but not the raw version are the ones relying on JS, and the ones to prioritize. I also disable JavaScript in the browser to see the bare experience Google starts from.
The two-crawl comparison is the most revealing test I run on a JS site. A big gap between the raw and rendered crawls, in word count, in links found, in titles present, is a direct measure of how much the site is betting on rendering working. The bigger that gap, the more fragile the rankings.
Rendering Strategies Compared
Where the HTML comes from is the single biggest factor in JS SEO. There are four broad strategies, and they are not equal for search. The goal is to get real content into the initial HTML response so rendering is not a prerequisite for being seen.

Client-side rendering ships an empty shell and builds everything in the browser, which is the riskiest for SEO. Server-side rendering returns fully formed HTML on each request. Static generation pre-builds HTML at deploy time, the fastest and safest. Dynamic rendering serves crawlers a pre-rendered version separately, which Google now treats as a workaround rather than a recommendation on web.dev.
How I choose for a client depends on how often the content changes. Mostly static content, like a blog or marketing site, should be statically generated; it is the fastest and the safest. Content that changes per request or per user wants server-side rendering. Pure client-side rendering is fine for the parts of an app behind a login, where SEO does not apply, and a poor default for anything that needs to rank. This split is the heart of SaaS SEO, where the marketing pages must rank while the product sits behind a login.
The Fixes I Apply
The fixes follow the diagnosis directly. If content is missing from the rendered HTML, the answer is almost always to render it server-side or statically so it ships in the initial response. For most framework sites that means turning on SSR or pre-rendering the routes that matter for search.
The smaller fixes are just as important. Replace JavaScript navigation with real anchor tags so links are crawlable. Unblock the JS and CSS resources in robots.txt so Google can render. Make lazy-loaded content reachable without interaction, and give infinite-scroll feeds real paginated URLs. None of these are exotic; they are the difference between a site Google can read and one it cannot.
Where JS SEO Fits in An Audit
JavaScript rendering is part of the technical phase of a full audit, sitting right alongside crawlability and indexation. A JS-heavy site that fails the rendered-HTML check has a foundation problem, and no amount of content or links fixes it until the content is actually visible. It is one of the first things I check, covered in the SEO audit checklist.
It is also a frequent culprit behind a sudden ranking loss after a redesign or migration to a new framework. When traffic drops right after a relaunch, a rendering regression is high on my list, which is why a JS check is part of any sudden traffic drop diagnosis.
JavaScript SEO and AI Crawlers
There is a newer reason this matters more than it used to. The crawlers behind ChatGPT, Perplexity, and other AI answer engines are mostly far less capable than Googlebot, and many do not execute JavaScript at all. They read the raw HTML and move on, which makes rendering a foundation of answer engine optimization.
So a client-side-rendered site that Google eventually sees through its render queue can be completely invisible to the AI crawlers that increasingly drive discovery. If you want a brand to show up in AI answers, the content has to be in the initial HTML. Server rendering is no longer just a Google optimization; it is the price of entry for AI visibility too.
This is not speculation. The Common Crawl Foundation, whose open dataset trains much of what these models learn from, has written about why your content must exist in AI training data. In his AI Visibility Audit field guide, their Web Intelligence Lead Stephen Burns is blunt that many AI crawlers "fetch HTML but may not execute JavaScript," so content that only appears after JS runs can be captured as an empty shell. His validation is the same raw-versus-rendered check I described above.
Common Mistakes
The biggest mistake is assuming Google "just handles JavaScript now" and moving on. It handles it on a delay, partially, and only for Google. Building a content site as a pure client-side app and hoping for the best is how sites launch invisible.
The other two repeat constantly. Treating dynamic rendering as a permanent solution, when Google has said to render properly instead. And testing only in the browser, which always runs the JavaScript and so never reveals the problem. If your only test is "it looks fine for me," you have not tested JS SEO at all.
Frequently Asked Questions
Does Google Index JavaScript Content?
Yes, Google renders and indexes JavaScript content, but on a delay through a render queue, and it indexes the rendered DOM rather than your raw HTML. Content that only appears after JS runs can be indexed late or, if rendering fails, not at all. Other search engines and AI crawlers handle JS far less reliably.
Is React or Next.js Bad for SEO?
No, not when rendered correctly. React on its own, rendered client-side, is risky because the initial HTML is empty. Next.js solves this by supporting server-side rendering and static generation, which put content in the initial HTML. The framework is fine; the rendering strategy is what decides SEO outcomes.
Is Server-Side Rendering Better Than Client-Side for SEO?
Yes. Server-side rendering returns content in the initial HTML, so Google sees it on the first crawl without waiting for the render queue. Client-side rendering ships an empty shell that depends on JS execution to show anything. For content that needs to rank, server rendering or static generation is the safer choice.
How Do I Test If Google Sees My JavaScript Content?
Use Search Console's URL Inspection tool to view the rendered HTML and screenshot Google generates, and compare it against your live page. If the main content or links are missing from the rendered HTML, Google is not seeing them. A JS-rendering crawl confirms the issue across the whole site.
Does JavaScript Slow Down My Site for SEO?
It can. Heavy JavaScript delays the first meaningful paint and can hurt Core Web Vitals, which are ranking signals and conversion factors. Excessive client-side work, large bundles, and slow hydration all add up. Reducing and deferring non-critical JavaScript, and rendering content server-side, addresses both speed and indexing at once.
Want Mojo Links To Audit Your JS Site?
If your site is built on a JavaScript framework and you are not certain Google sees all of it, that uncertainty is worth resolving before it costs you rankings. We run the rendered-HTML checks and the full technical pass for clients. The free SEO growth audit includes a technical health read that flags rendering problems before they become a traffic loss.

About Bart Magera
Bart Magera is the founder of Mojo Links. Ten years across YMYL verticals (legal, medical, finance, supplements, crypto, gambling). Trained under Koray Tuğberk Gübür's Topical Authority framework. Author of two SEO books and international speaker.
Want this kind of analysis on your site?
Get a free video walkthrough within 48 hours covering technical health, backlinks, content gaps, and AI visibility.
Related posts
Keep reading on adjacent topics.
- SEO
 Bart Magera9 min read
Bart Magera9 min readBrand Mentions for SEO: Linked, Unlinked, and AI Citations
Most SEO budgets still treat a mention without a link as a failed pitch. That math is out of date. The same editorial naming that builds your entity in Google now decides whether AI engines name you in answers. Here is the value model behind linked, unlinked, and AI-cited mentions, and the three lanes for earning more of them.
- SEO
 Bart Magera12 min read
Bart Magera12 min readAI Visibility Tools: 9 Trackers Ranked for Client Work
Nine AI visibility tools, one yardstick: engines covered, what gets measured, competitor tracking, and price. Every page-one comparison of these trackers is written by a vendor ranking its own product first. This one is not. Here is where each tool fits, from a $29 entry plan to enterprise quotes, and the one thing none of them can do.
- SEO
 Bart Magera10 min read
Bart Magera10 min readChatGPT Brand Mentions: How To Track and Earn Them
When a buyer asks ChatGPT for the best option in a category, it names a few brands inside the answer. Those ChatGPT brand mentions, not the linked citations beneath them, are what get you recommended. Here is how to track them and how to earn them.